
Có một sự thay đổi bất ngờ trong quan niệm trước nay, khi Intel đã chứng minh rằng đối với máy dịch (machine translation), sử dụng RNN, bộ vi xử lý Intel Xeon Scalable có thể đạt hiệu năng tính toán vượt trội so với các hệ thống dựa trên NVidia V100 đến bốn lần.
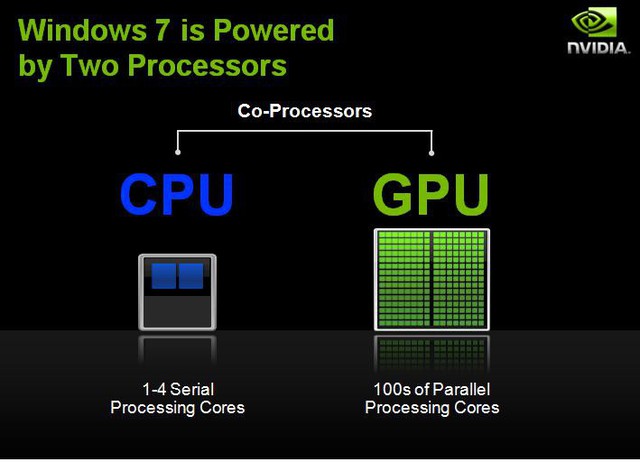
Chúng ta đã được chứng kiến rất nhiều cuộc so sánh về khả năng xử lý của CPU và GPU. Và kết quả là GPU luôn tỏ ra vượt trội hơn. Nguyên nhân do CPU được thiết kế chỉ một vài nhân để xử lý tối ưu một chuỗi các tính toán nối tiếp nhau, trong khi GPU có kiến trúc nhiều lớp song song bao gồm đến hàng ngàn nhân nhỏ hơn và hoạt động hiệu quả hơn để xử lý nhiều công việc cùng lúc. Do đó, GPU thường được dùng để tăng tốc hiệu suất hoạt động trên hầu hết các nền tảng khác nhau.
Intel đã thực hiện một bản demo tại các phòng thí nghiệm ở Oregon sử dụng loại máy dịch AWS Sockeye Neural Machine Translation (NMT) với Apache *MXNet* và sử dụng Intel Math Kernel Library (Intel MKL). Và kết quả cho thấy, đối với máy dịch sử dụng RNN, bộ vi xử lý Intel Xeon Scalable có khả năng xử lý nhanh hơn NVidia V100 đến 4 lần.

Để đạt được tốc độ như vậy, RNN là một recurrent neural network (mạng thần kinh tái phát), và đây là một lớp artificial neural network (mạng thần kinh nhân tạo) trong đó các kết nối giữa các đơn vị tạo thành một đồ thị theo hướng dọc theo một chuỗi.
Trước đây, để đào tạo - suy luận deep learning trên CPU phải mất tốn khá nhiều thời gian không cần thiết vì phần mềm không được viết để tận dụng đầy đủ các tính năng và chức năng của phần cứng. Điều này cho thấy vấn đề khiến khả năng xử lý của CPU bị hạn chế nhiều khả năng là do phần mềm. Và hiện tại đây đã không còn là vấn đề. Bộ vi xử lý Intel Xeon Scalable với phần mềm được tối ưu hóa đã chứng minh đạt hiệu suất rất lớn cho việc deep learning so với các thế hệ trước mà không có phần mềm được tối ưu hóa.
Kết quả này ngoài việc áp dụng cho các loại recurrent neural network (RNN) khác nhau, còn có thể áp dụng với các loại mô hình khác như multi-layer perceptron (MLP) (perceptron đa lớp), convolutional neural networks (CNN) (mạng thần kinh xoắn ốc). Giờ đây, khoảng cách về hiệu suất giữa GPU và CPU trong việc đào tạo và suy luận deep learning đã được thu hẹp và thậm chí các CPU giờ đây có thể có lợi thế hơn GPU trong một số công việc xử lý.
Intel hiên cung cấp khá nhiều thông tin chi tiết hơn trong các blog của họ và thậm chí có cả một bản demo bằng video được trình diễn bởi Vivian TJanecek thuộc ban Tiếp thị Trung tâm Dữ liệu của Intel và Sowmya Bobba - kỹ sư ML của Intel. Bạn có thể thấy rõ rằng hệ thống cơ sở của Intel đạt 93 sentence mỗi giây trong khi máy Nvidia V100 chỉ đạt 22 sentence mỗi giây.
Các thí nghiệm được thực hiện bằng cách sử dụng các máy chủ tại Amazon Web Services (AWS) với framework Apache MXNet công cộng. Điểm benchmark được sử dụng là AWS Sockeye. Nếu bạn quan tâm về khoa học dữ liệu thì nên ghé thăm blog và xem video từ Intel - chắc chắn nó sẽ rất hấp dẫn đối với bất kỳ nhà khoa học dữ liệu nào.
CÙNG CHUYÊN MỤC








